Before generating a language, you can add custom words to the Add and remove words. Use the format English word : part-of-speech

The part-of-speech is optional, but necessary for the word to work in the Translator, and should be in the abbreviate form (n = noun, v = verb, etc).
To specify what the conlang word will actually be, add = conlang word (in IPA):
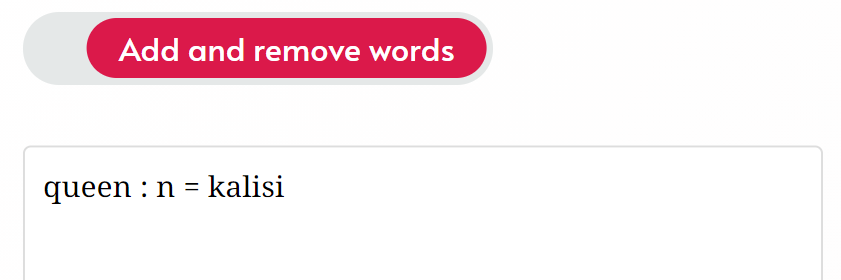
This makes kalisi be the pronunciation of the word (not the surface spelling!)
If you’ve already generated a language (either by loading a saved language, or by clicking Edit This Language), you can now change the vocabulary in the Add and remove words field. Remember to re-generate the language after making changes! Click Apply New Changes at the top of the app.
Irregular spelling ![]()
Irregular spelling can be specified for a word after the conlang part (IPA) in between <angled brackets>
This will override any regular spelling rules specified in the Spelling options of the app.
Removing words ![]()
After clicking Edit This Language, you can remove a dictionary entry by simply deleting the line from the Add and remove words field. You can also prevent a word from ever being generated by subtracting the word in Add and remove words:
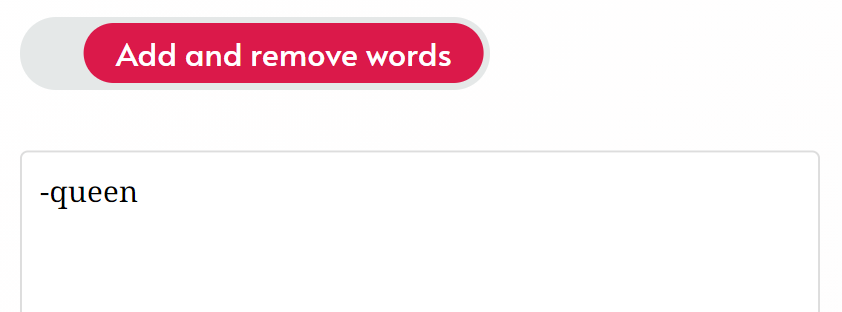
Note: When using the subtract method, it is not necessary to write the part-of-speech (unless there are two entries of the word with different parts-of-speech and you only want to remove one of them).
Derived words ![]()
Derived words are words that are built out of other words. For example, “government” is made up of the root verb “govern” and the affix “-ment”. We are able to simulate these kinds of words in the Derived words field. The format is new word : part-of-speech = existing word-AFFIX.TAG

Vulgar has various default affixes already populated in the Add or modify affixes field. You can create brand new affixes in this field. For instance, Vulgar does not automatically create an affix for the opposite of something, as in English’s “un-” prefix. So you may choose to create this affix in Add or modify affixes:
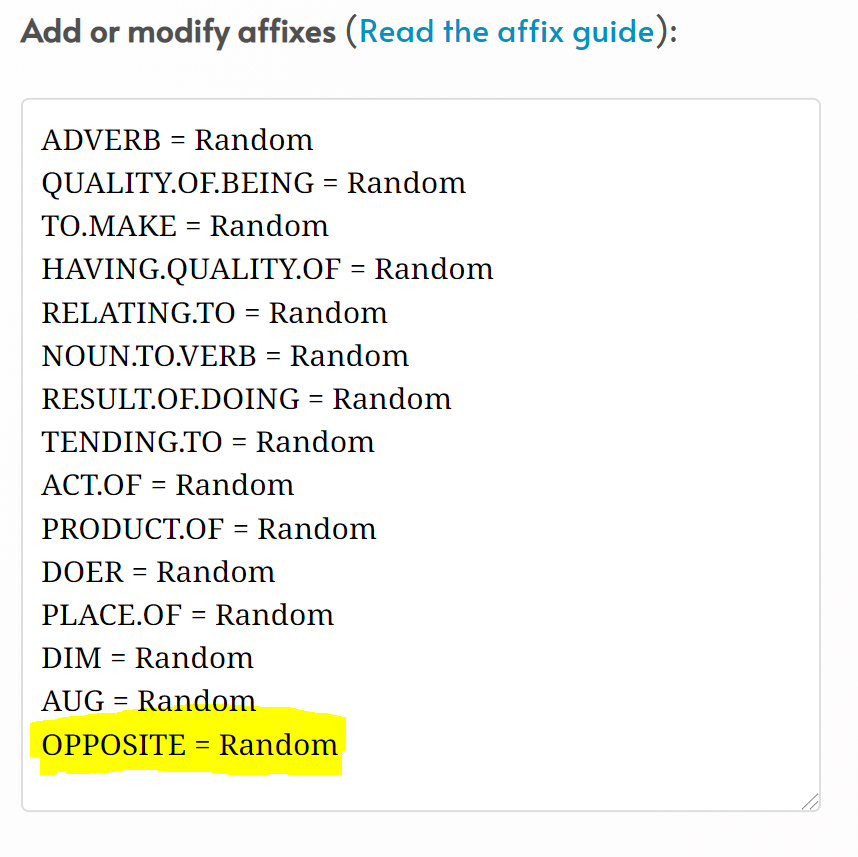
The affix tag name can be whatever you want, but it must be in capitals (to distinguish it from a regular word) and can optionally have numbers or a full stop.
= Random means Vulgar will randomly create the affix for you. You can now use -OPPOSITE on words in the Derived words box:

Be creative with affixes! Maybe your language uses affixes for things instead of full words, like:
Affixes can be stacked on each other:
In this scenario, QUALITY.OF.BEING first changes “happy” to “happiness”, next the OPPOSITE affix is added.
If the root word you’re trying to pull from the dictionary has two possible parts-of-speech (such as “laugh” as a verb and “laugh” as a noun), you can specify the part of speech like this:
If there are two conlang words with the same English-word translation and they have the same part-of-speech, you may disambiguate them in Add And Remove Words using subscript or superscript numbers:
home₂ : n = casa
Now it is possible to create a derived word that targets the second entry specifically:
Defining your own affixes ![]()
Instead of using = Random, you can define what your custom affixes actually are in the following format:

This creates a suffix. A root word such as ama would change to amas
To create a prefix, the
This changes ama to sama. Even though this is a prefix, the affix tag can be positioned after the word, e.g. happy-OPPOSITE, although OPPOSITE-happy is also valid.
The following rule attaches a circumfix:
This changes ama to samas. Again, the OPPOSITE tag can be positioned before or after the root word, however, for consistency, it’s better to put everything after the word.
Affixes that are separate words ![]()
You can encode a whole word into an affix by separating the hyphen by a space:
This changes ama to not ama.
Sound changes ![]()
Sound changes can be encoded into an affix tag using the > symbol
This would change ama to imi.
You may want to only change the final a in the word. To do this use >>
This changes ama to ami. Similarly, you can change the first match with <<
All the standard sound change notation can be used, eg:
Use semicolons
This changes ama to abis.
Infixes ![]()
Infixes are affixes that go in the middle of a word. In Spanish, the infix -it- turns a word into a diminutive: gato (“cat”) changes to gatito (“little cat”). In the linguistic/conlanging community, the convention is to write infixes with hyphens either side of the infix (-it-). The problem with this is that it does not tell us where in the word the infix should go. In Vulgar, the solution is to use a sound change that changes nothing to something in a particular environment:
This means “nothing” (represented by the null symbol ∅) between a consonant (C) and a vowel at the end of word (V#) changes to it. The null symbol can even be omitted:
Changing to multiple choices ![]()
A choice between random affixes can be created using the bar symbol |. The following rule adds either an -s, -t or -p as the affix:
Similarly, the resulting sound change can be randomised with the | symbol:
Conditional IF and ELSE statements ![]()
There may be scenarios where you want to create conditional rules. You can do this based on whether a sound change pattern is found in a word:
For instance, let’s say your prefix is s-, but if the root word already starts in an s you want to the prefix to se- to avoid a double s. The # symbol represents a word boundary. So we can say:
This changes sama to sesama, while ama changes to sama. Note that IF, THEN and ELSE must be capitalised.
The ELSE condition is optional and can be omitted. Multiple IF statements are permitted:
Rules can be split over multiple lines (and indented) to make them easier to read:
IF #s THEN
se-
IF s# THEN
-e
ELSE
s-
In Vulgar, secondary IF statements are technically what other programming languages call “ELSE IF” statements. Meaning, they don’t get tested if a previous IF condition is satisfied. To create a truly independent IF statement, you need to break up the rules up with a semi-colon
In this example, a word such as sas changes to sesase, because both IF statements are tested and both are satisfied. Without the semi-colon, it does not test the second IF. If you want to do sound changes within a single condition, you need to use regular comma instead. For example,
IF statements can apply affixes that match the vowel harmony of root word. Let’s say you have a vowel harmony system of front vowels i e a and back vowels u o.
NOT (!) and AND (&) operators ![]()
Use & to test for multiple conditions:
This tests that the word both begins with and ends with a vowel.
Use ! to test that it does not match a condition:
This tests that the word does not start with se.
Explaining it all in English ![]()
Vulgar sometimes has a difficult time translating complex rules into plain English. If the program is struggling, you can write your own plain English explanation under the rule, starting with a double quote character
IF #s THEN
se-
IF s# THEN
-e
ELSE
s-
”If the word begins with s, add se-.
Else if it ends with s, add -e.
In all other cases add s-.
NEXT.RULE =
Single use affixes ![]()
The affix tag
Compound words ![]()
Let’s say your word for “war” is kara and your word for “God” is kin, and you want a compound of those words karakin to mean “God of War”. Add the two English words connected with a hyphen:
Separating the words by a space creates kara kin:
Bound roots ![]()
Sometimes you want to create a root word that doesn’t exist as a stand-alone dictionary entry and is only found with affixes attached to it. An example in English would be words like “absence” and “absent”, where it is somewhat unclear whether “absence” actually derives from “absent” or if they both derive from a common root “absen”.
These are known as “bound roots”, since they must be bound to something else. To create a bound roots, add them to Add and Remove Words with the special part-of-speech root, eg:
Now absen can be used in the derived words section to create other words. Make sure the names of bound roots aren’t the same as other English words!

Just like other custom word, you can define what the bound root what is in IPA: