The Grammar Editor has two main functions: firstly it functions as a text editor where you can simply write about your language in plain English — create sections and headings for different topics in your language.
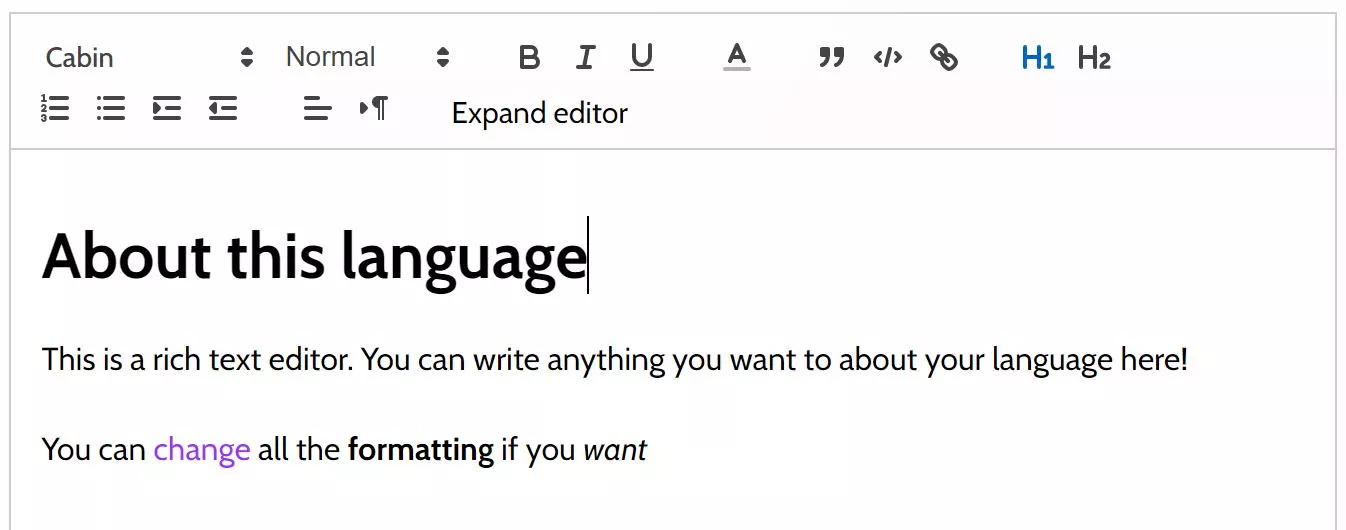
Secondly, it allows you to insert special “grammar table” code blocks, which generate grammatical affixes and words in a neat tables. It also provides rules to the Translator for how to apply affixes in sentences.
Affix tables ![]()
Insert an affix table into Grammar Editor using the Add Grammar Table button. The example below inserts a code block into the Editor that will create a table for past, present and future tense affixes:
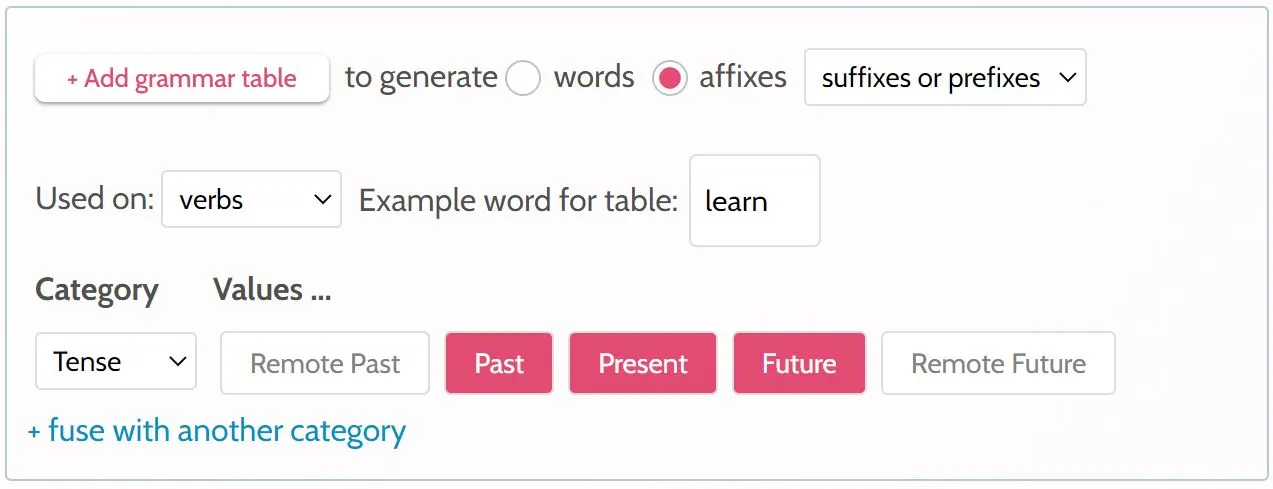
Once inserted to the Editor, the code looks like this:
TABLE TYPE = affix part-of-speech = v example-word = learn rows = PaST / PReSent / FUTure PST ~ learned = Random PRS ~ learn = Random FUT ~ will learn = Random
Then upon generating the language, the table will come out something like this:
| Past | Suffix -a learned |
| Present | Suffix -e learn |
| Future | Suffix -i will learn |
In this language, the base word for “learn” is
Here is a explanation of what all the code means, and how it can be edited to suit your liking:
With the affix button selected, this inserts

The Used on option means that these affixes are only meant to attach to verbs. It inserts
Example word for table tells the app to use the conlang word for “learn” (

The Categories and Values options is for what kinds of grammatical concepts (values) you want to generate an affix for. These values are placed at beginning of each row (

This is where you can start to get creative! Maybe you want your language to have both a past tense and a “remote past” tense for things that happened a long time ago (a feature in Italian). Perhaps your language has no future tense affix. Note that English has no future tense affix. It still has a way of expressing things that happen in the future using the word “will”, it just has no future tense affix. Whereas other languages, such as Spanish, have an affix for future tense.
Changing the category shows you different kinds of grammatical values that can be expressed via affixes.
Custom categories ![]()
Vulgarlang does not list all possible grammatical values that can be expressed in affixes. Let’s say you want to add a recent past tense. Select the custom category and manually type in values:

Separate custom values with forward slash (or comma).
Defining affixes ![]()
Inside the code block
TABLE TYPE = affix part-of-speech = v example-word = learn rows = PaST / PReSent / FUTure PST = -ed PRS = FUT = will-
produces:
| Past | Suffix -ed |
| Present | No affix |
| Future | Prefix will- |
This example partly mimics English:
There is much much more that can be done with custom affixes, so check out the complete guide here.
You can optionally translate each cell by writing
TABLE TYPE = affix part-of-speech = v example-word = learn rows = PaST / PReSent / FUTure PST ~ learned = -ed PRS ~ learn = FUT ~ will learn = will-
Result:
| Past | Suffix -ed learned |
| Present | No affix learn |
| Future | Prefix will- will learn |
Fusional vs agglutinative affixes ![]()
Clicking + fuse with another category adds another grammatical category into the same table, by adding multiple columns for each row. This means that each affix will express two grammatical categories. Affixes that express multiple grammatical categories are said to be “fusional”. In the below example, each affix expresses tense (either past, present or future), as well as person (whether the verb is being done by a 1st, 2nd or 3rd person):
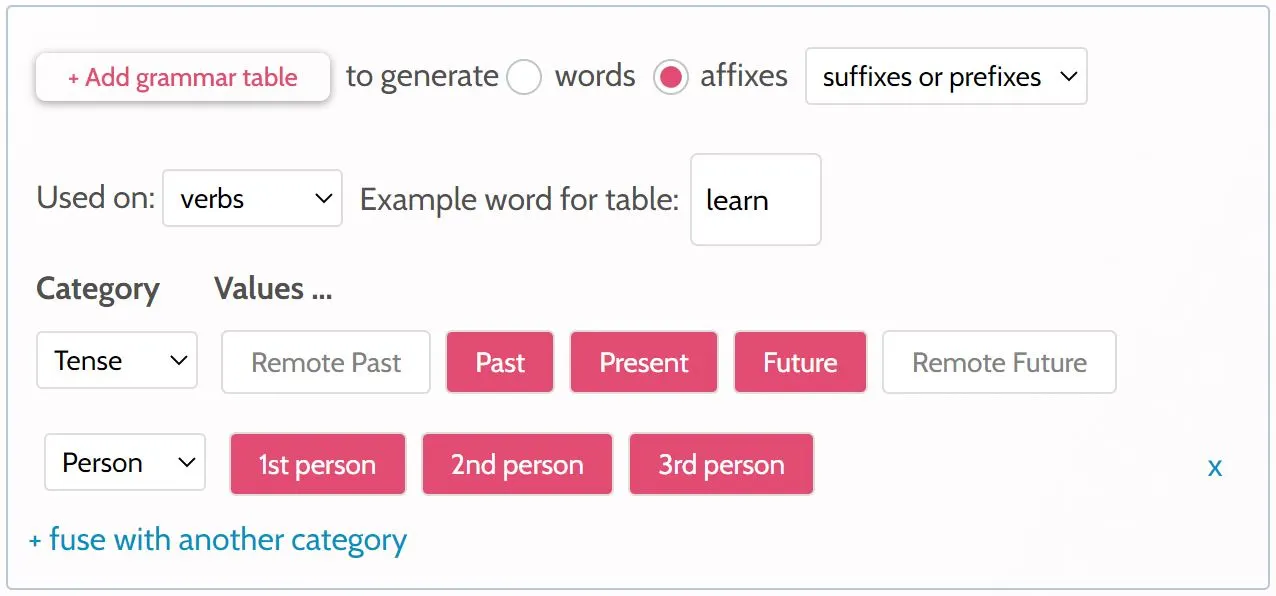
TABLE TYPE = affix part-of-speech = v example-word = learn rows = PaST / PReSent / FUTure cols = 1st person / 2nd person / 3rd person PST.1 = -a PRS.1 = -b FUT.1 = -c PST.2 = -d PRS.2 = -e FUT.2 = -f PST.3 = -g PRS.3 = -h FUT.3 = -i
Result:
| 1st person | 2nd person | 3rd person | |
| Past | Suffix -a |
Suffix -d |
Suffix -g |
| Present | Suffix -b |
Suffix -e |
Suffix -h |
| Future | Suffix -c |
Suffix -f |
Suffix -i |
Here, the suffix
By contrast, agglutination is where a each affix express just one grammatical category, however multiple affixes may be added strung together. To create agglutinative affixes, you effectively need to create two separate tables, one for tense and another for person.
Tense table:
TABLE TYPE = affix part-of-speech = v example-word = learn rows = PaST / PReSent / FUTure PST = -a PRS = -b FUT = -c
Person table:
TABLE TYPE = affix part-of-speech = v example-word = learn rows = 1st person / 2nd person / 3rd person 1 = -d 2 = -e 3 = -f
Now the translation for “I learned” would require the past tense suffix
Irregular words ![]()
If you want a word to have its own irregular affixes, you need to create a whole extra table and manually enter the line
TABLE TYPE = affix part-of-speech = n example-word = dog irregulars = vulp rows = SinGular / PLural SG ~ dog = PL ~ dogs = -i
A single irregular table can target multiple words by comma separating them, e.g.
Multiple example words ![]()
If your language has noun genders, you will probably want to use example words from the dictionary for each gender:
TABLE TYPE = affix part-of-speech = n example-word M = dog example-word F = cat cols = Masculine / Feminine rows = SinGular / PLural M.SG ~ dog = Random M.PL ~ dogs = Random F.SG ~ cat = Random F.PL ~ cats = Random
This applies the Masculine Singular and Masculine Plural affix to “dog”, and Feminine Singular and Feminine Plural affix to “cat”. Note that you need to know the genders of these words beforehand to do this; the program will not automatically make “dog” masculine just because your table says it’s masculine.
Multiple parts of speech ![]()
In some languages, affixes pattern the same way for multiple parts-of-speech. Instead of adding two tables you can comma separate multiple parts of speech. For example this creates the same affixes for nouns and adjectives:
part-of-speech = n, adj
Note that this does not create two tables (nor should it, since the example word would be a noun in this scenario!) it just creates the affixes for adjectives in the backend, ready to used in the Translator. Don’t forget that you can always simply write about your language outside of the grammar tables and mention that “affixes for adjectives pattern the same as nouns”.
Plain English explanations for rules ![]()
Vulgarlang sometimes has a difficult time translating complex rules into plain English. If the program is struggling, you can write your own plain English explanation under the rule, starting with a double quote character:
TABLE TYPE = affix part-of-speech = n example-word = dog cols = SinGular / PLural SG = -s PL = IF #C & C# THEN -z ELSE -a "If the word begins and ends in a consonant, add -z to the end. Otherwise add -a to the end
Result:
| Singular | Suffix -s |
| Plural | If the word begins and ends in a consonant, add -z to the end. Otherwise add -a to the end |
Comments ![]()
Comments are a similar concept to Plain English explanations, except that they do not get added to the output anywhere; they are simply helpful notes while editing. Comments are written with double forward slashes // up to the end of a line:
SG = -s PL = IF #C & C# THEN -z ELSE -a // This text gets completely ignored by the generator! //
Comments can also be used in all other input options in Vulgarlang, such as the Sound Change option (which is what they were primarily used for).
Word tables ![]()
Words generated in word tables automatically get pushed into the main dictionary. Same as affix tables, you can specify what the word will be using the equals sign:
TABLE TYPE = word part-of-speech = det cols = Masculine / Feminine rows = SinGular / PLural M.SG = el F.SG = la M.PL = los F.PL = las
And you can specify exactly what each word translates to in the dictionary using the
TABLE TYPE = word part-of-speech = det cols = Masculine / Feminine rows = SinGular / PLural M.SG ~ the (masculine singular definite article) = el F.SG ~ the (feminine singular definite article) = la M.PL ~ the (masculine plural definite article) = los F.PL ~ the (feminine plural definite article) = las
Pronoun tables ![]()
Some confusion can arise with English pronouns, due to the fact that gender is only expressed in some of its pronouns. English’s 3rd person has three genders: “he”, “she” and “it”. However, all other pronouns are gender neutral: “I”, “we”, “you”, and “they”.
Furthermore, English doesn’t have a singular/plural distinction in the 2nd person “you”, whereas 1st person does (“I” vs “we”) as does 3rd person (“he/she/it” vs “they”).
This inconsistency makes it difficult to divide English pronouns neatly into Vulgarlang’s rows and columns. The simplest thing may be to select the “custom” category and put every pronoun own its own row, like this:
TABLE TYPE = word part-of-speech = pron rows = 1st person SinGular / 2nd person SinGular / 3rd person Masculine SinGular / 3rd person Feminie SinGular / 3rd person Neutral SinGular / 1st person PLural / 2nd person PLural / 3rd person PLural 1.SG ~ I = Random 2.SG ~ you = Random 3.M.SG ~ he = Random 3.F.SG ~ she = Random 3.N.SG ~ it = Random 1.PL ~ we = Random 2.PL ~ you = Random 3.PL ~ they = Random
However this is still not the full picture! English has different set of pronouns for “cases”, which change based on who is doing the verb (I, he, we, etc.) vs who the verb is done-to (me, him, us, etc.). Linguists call these the Nominative and Accusative case, respectively. So you may choose to add an axis for Nominative and Accusative case:
TABLE TYPE = word part-of-speech = pron rows = 1st person SinGular / 2nd person SinGular / 3rd person Masculine SinGular / 3rd person Feminie SinGular / 3rd person Neutral SinGular / 1st person PLural / 2nd person PLural / 3rd person PLural cols = NOMinative / ACCusative 1.SG.NOM ~ I = Random 1.SG.ACC ~ me = Random 2.SG.NOM ~ you = Random 2.SG.ACC ~ you = Random 3.M.SG.NOM ~ he = Random 3.M.SG.ACC ~ him = Random 3.F.SG.NOM ~ she = Random 3.F.SG.ACC ~ her = Random 3.N.SG.NOM ~ it = Random 3.N.SG.ACC ~ it = Random 1.PL.NOM ~ we = Random 1.PL.ACC ~ us = Random 2.PL.NOM ~ you = Random 2.PL.ACC ~ you = Random 3.PL.NOM ~ they = Random 3.PL.ACC ~ them = Random
If you want to make a different pronoun system to English, you need to decide if you want your conlang’s pronouns to fit neatly into the rows and columns of a table, or if there will be some level of irregularity, like the English system.
Other tricks ![]()
Getting words from the dictionary ![]()
In the body of the grammar editor, you may pull conlang words from the dictionary using double curly brackets around the English word, eg: {{man}} will be replaced with the conlang word for man. This is helpful if you don’t know the word ahead of time. You can also apply affixes to this, eg: {{man-PL:N}} will add the plural form for nouns (assuming your language has this affix).
Be aware that although the affix abbreviation would have been
{{Langname}} can be used to pull the language’s name.
Boxed sections ![]()
Create boxed off sections in your grammar by typing three dashes in the Grammar Editor.
---
Plain tables ![]()
Plain tables (that don’t generate anything) can be inserted inside a code-block using Markdown-style formatting:

Result:

Gloss translations ![]()
Code blocks also allow you to create gloss translations (word-for-word and morpheme-to-morpheme translations):
Example:
te wunua molengo-su CASE house old-1SG.POSS my old house
Result:

The 1st line is the of the code is the conlang translation, the 2nd line is the gloss, and the last line (optional) is the plain English translation. The 1st and 2nd line should have the exact same number of spaces in order for the word-for-word translation. You can optionally put intermediary translations before the last line.
Note: even though this uses affix tags in a similar fashion to other areas in Vulgarlang, this section does not do the translation for you. Why? Because Vulgarlang’s affix tag system only partially replicates a proper linguistic gloss. For instance, you can encode an circumfix into a single affix tag. However the glossing convention is to show a morpheme-to-morpheme correlation, which means the circumfix tag should be shown at the beginning at the end of the word:

Manual translations also allow you to mark the morpheme boundaries in the conlang word, and follow other glossing conventions.