Vulgarlang is an application both for people who don’t know anything about how to create a language, and just need something created quickly for a story or RPG, as well as advanced conlangers who want to be able to customize every little detail of their language.
For those new to conlanging, you can simply press Generate New Language — the generator will decide which sounds your language has, assign words to English definitions, and also come up with grammar rules.

You may want to click Custom Phonemes to tell the generator which consonants and vowels you want your language to have:

We often hear people say ‟I have a race of dwarves/orcs/elves in my story; I want their language to sound something like German/Latin/Mongolian, but I can’t figure out how to do it!” Here is a quick hack!
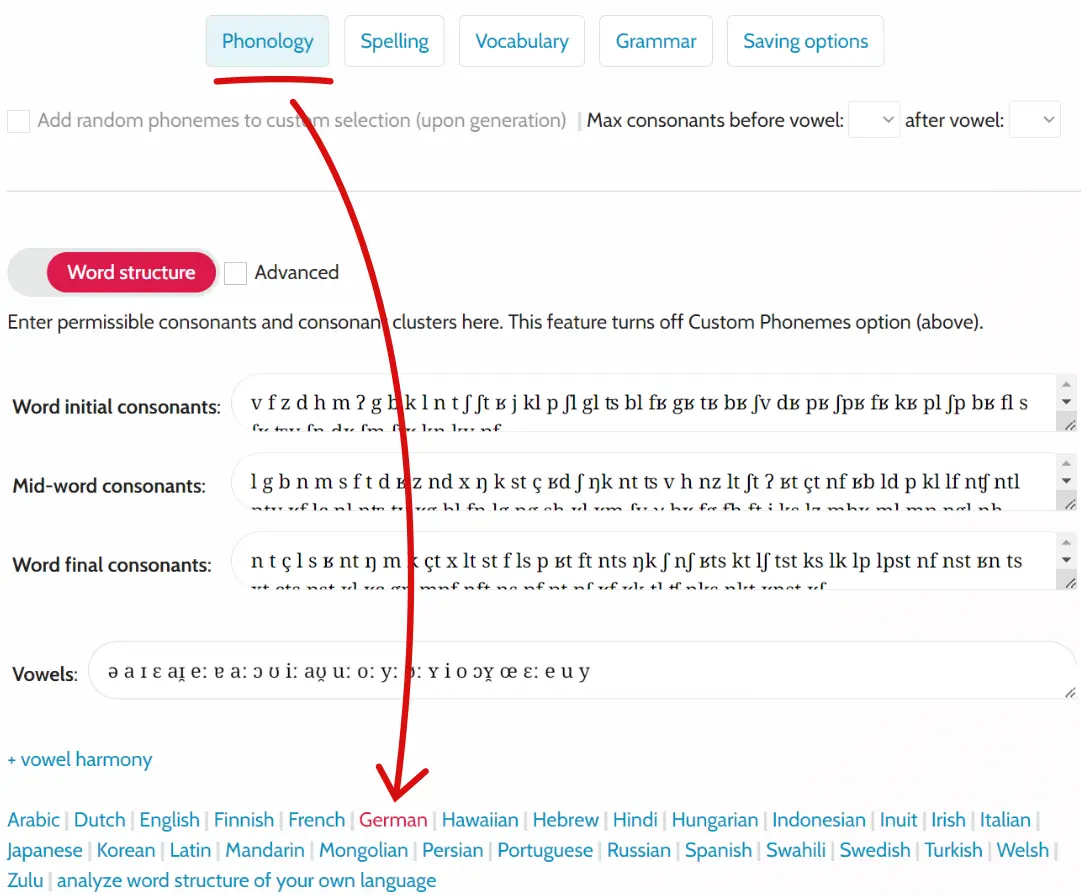
- Click the Phonology settings
- Click Word structure option
- Choose one of the presets of a languages, e.g. German
- Click Generate New Language
And you should get a language that looks kind of like German!

This may be all you need from Vulgarlang. However, you may also want to get their hands a little more dirty with the language creation, and maybe even learn a thing or two about linguistics as you go along.
Vulgarlang can indeed look quite overwhelming at first. The field of linguistics it a bit of a rabbit hole, and it may surprise you that the fictional languages created for some of the best know franchises (The Lord of the Rings, Star Trek, Game of Thrones) are more than just lists of new words. They are carefully crafted languages with complex grammar rules, that have striven to feel different to English. In fact, one of the biggest pieces of advice in conlanging is: don’t just copy what English does!
However, it’s hard to not copy English if English is all you know. Without having studied a range of languages from around the world, you probably don’t know what you don’t know. For example, did you know:
-
- some languages change up the order of words and end up being closer to how Yoda speaks, e.g. ‟strong is he” instead of ‟he is strong”
- some languages use the same word for ‟blue” and ‟green”
- some languages say a word twice to indicate the plural, e.g. ‟cat cat” to mean ‟cats”
This, of course, doesn’t even scratch the surface!
This article will briefly explain some of the main things you might want to take control over, such as the sounds and spelling, as well as editing individual words. Meanwhile, our guides page drills down into more detail on each topic. We also have a great YouTube channel on various topics.
Sounds and spelling
We’ve already seen two ways to control the consonants and vowels of your language. The easiest option is Custom Phonemes which tells the generator I at least want these phonemes. You decide which consonants are and aren’t allowed to appear next to each other.
The next most advanced option is the Word Structure option, which allows the user to decide which consonants are allowed to appear at the beginning, middle and end of a word, as well as which consonants are allowed to appear next to each other. It’s a lot more decision making, but sometimes you need to do this to get the ‟vibe” of your language right.
Note that we’re using the word ‟phoneme” and not ‟letter”. Phonemes are the individual sounds of a language, which is not the same as the spelling! Phonemes are represented by the International Phonetic Alphabet (IPA), which is used to transcribe the exact pronunciation of words in all languages worldwide, and can even account for regional accents. The IPA is a standardized, objective way to pronounce words: something that is not possible to do with the Latin alphabet. For example, the Latin alphabet only has five vowel letters, A, E, I, O and U, yet there are more than 30 distinct vowel sounds found in languages around the world (not to mention the dozens of variations on how they can be pronounced).
Despite its usefulness, the documenting your conlang in IPA has some drawbacks. For one, it’s difficult to type on computers. Secondly, the average person wouldn’t understand it, and therefore wouldn’t actually have a clue how it’s meant to sound. For these reasons, conlangers usually create a spelling convention for their languages using the Latin alphabet, sometimes called a ‟romanization”. This is a good middle ground; it tells readers roughly what the language sounds like, without confusing them. It may not critical for your readers to know exactly how the language is pronounced anyway. And the IPA is always there for anyone who’s interested.
In Vulgarlang, the spelling is represented as bold blue text, whereas the IPA is written between /forward slashes/.

When you let the app decide the spelling convention, it tries to come up with how English speakers would pronounce the word. In the above example, the iesh /aɪ̯ʃ/, /ʃ/ is the IPA symbols for sh as in ‟show”. So the app choses sh too. But /aɪ̯/ is a vowel combo as in ‟eye“, ‟lie” and ‟sky”. There is no consistent way to spelling this English. Vulgarlang happened to choose ie for this one. In reality there may not be any great choices for /aɪ̯/, as ie can be used for the vowel in ‟believe”.
In cases where the word contains non-English phonemes, the app makes a spelling that is close to how it sounds in English. For example, the phoneme /ʈ/ is not found in English, but is found in some languages in India (e.g. Hindi). It sounds very similar to English /t/ as in “time”, but perhaps if you imagine it done in an Indian accent. /ʈ/ will be spelled t so long as the language doesn’t also have /t/. If it has both /t/ and /ʈ/, the latter will be spelled with some kind of diacritic mark, such as ṭ.
If you don’t like Vulgarlang’s default spelling choices, you are free to change the spelling rules in spelling options. Here is how to change /aɪ̯/ to how it’s spelled in “buy” and “guy“:

Editing the words
Before generating a language, you can add custom words to the Add and remove words. Use the format English word : part-of-speech.

Part-of-speech refers to whether the word is a noun, verb, adjective, etc., but we use the abbreviated form (n = noun, v = verb, adj = adjective, etc). If you don’t know the part-of-speech of any word, check an online dictionary.
Adding words this way makes the generator randomly generate a conlang word the two new entries, using the phoneme patterns you’ve selected. To specify what the conlang word will actually be yourself, add = conlang word (in IPA):
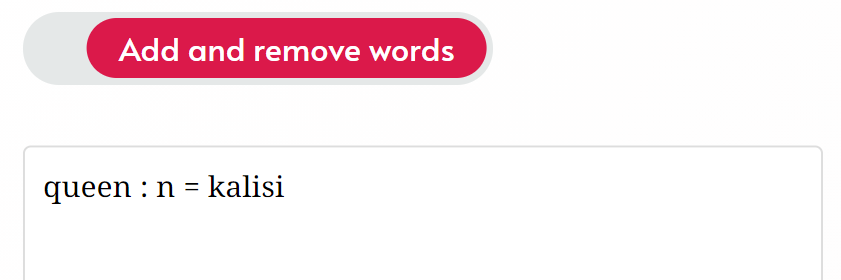
This makes kalisi the IPA pronunciation of the word, not the spelling! Your spelling rules will determine how the word is spelled (for this particular case, the default spelling will also be kalisi since the word doesn’t have any non-Enlgish phonemes).
If you’ve already generated a language (either by loading a saved language, or by clicking Edit This Language), you can now change the vocabulary in the Add and remove words field. Remember to re-generate the language after making changes!